* Introduction
* What is Caching ?
* Different Caching Location.
o Client Caching
o Proxy Caching
o Reverse Proxy Caching
o Web Server Caching
* Advantages and Disadvantages of Caching
* Caching Opportunity in ASP.NET
* Different Types of Caching
o Page Output Caching
o Fragment Caching
o Data Caching
+ Caching Dependency
# File Based Dependency
# Key Based Dependency
# Time Based Dependency
* Caching Considerations
o Output Caching Considerations
o Data Caching Consideration
* Suggested Uses of Caching Types
In our last project we have developed a sites for a large number of user, Larger number of client means large number of request to your web server, heavy load on network, cause performance issue. For solving this problem I have worked on using of caching on our web application. Now I think why should not I write one article on Code project on it. I am writing this article that what ever I have learned from my Practical Experience, Net Surfing and Different Books for completing my assignment . Most of the thinks are very common to maximum of reader, but I have tried to write some different way that it can be understandable by all beginners also. Main interest that I have found while writing the article that setting up the different location for caching, I have also given the corresponding Visio Diagram also. Hope You will definitely like it.
Web applications are accessed by multiple users. A web site can have an extremely low load for minimum number of client access which provide faster access of the sites or may be heavy load on the site can increase exponentially which can slow down the server as well as access of Sites . Slow access is the most common problem for any web site when it is accessed by a large number of client simultaneously. For resolve this problem we can have used high level of hardware configuration, Load Balancer , High bandwidth but load is not the only reason that make a web site is slow , so we need to provide such kind of mechanism which also provide fast data access and provide performance improvement of web site. Caching provide the solution.
Caching is a technique where we can store frequently used data and Web pages are stored temporarily on local hard disks for later retrieval. This technique improves the access time when multiple users access a Web site simultaneously or a single user accesses a Web site multiple times. Caching for Web applications can occur on the client (browser caching), on a server between the client and the Web server (proxy caching / Reverse Proxy Caching), and on the Web server itself (page caching or data caching).
Maximum time we chose web server to store cached data though it improved the performance but it does not solve our purpose every time. If we consider about load on Web Server we have to consider about the location that when the cached data should store. Following section will describe on different location of storing cached data.
Caching in a web application can be done either on client side (Client Browser), In between Client and Server (Proxy & Reverse Proxy Caching ) and on Server Side( Data Caching/ Page Output Caching) . So we can classified caching location in 4 way
- Client Caching
- Proxy Caching
- Reverse Proxy Caching
- Web Server Caching
1. Client Caching : In Client Caching Client Browser perform caching by storing cached data on local disk as temporary file or browser internal memory. This provide quick access of some information by client which reduce the network load and server load also. This information can't be shared by other clients so it is client specific.
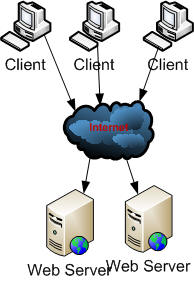
Fig 1.0 : Client Caching
Advantages
- Data that are cached on local client can be easily accessed
-
Reduce Network Traffic
Disadvantages
-
Cached data are totally browser dependent, so it is not shareable
2. Proxy Caching : Main disadvantage of Client caching was data that are store on client browser are client specific. Proxy Caching technique used a dedicated server that store caching information in between client and web server in a shared location, that all client can used same shared data. The proxy server (e.g. Microsoft Proxy Server ) fulfills all the requests for the Web page without sending out the request to the actual Web server over the Internet, resulting in faster access.
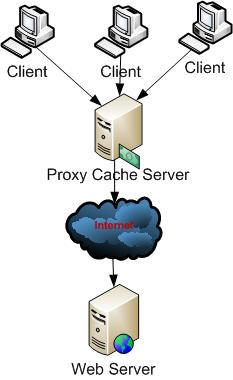
Fig 1.0 : Proxy Caching
Proxy caches are often located near network gateways to reduce the bandwidth . Some times Multiple Proxy Cache server is used for larger number of client. This is called Cache Array.
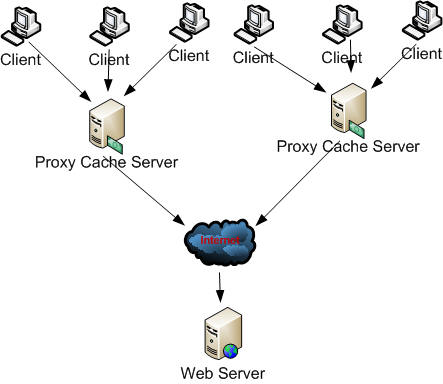
Fig 1.1 : Cache Array
Advantages
- Data that are cached on proxy server can a accessed easily
- Reduce Network Traffic
Disadvantages
-
It a Deployment and Infrastructure overhead to maintain a Proxy Cache Server
3. Reverse Proxy Caching : Some Proxy Cache server can placed in front of web server to reduce the number of requests that they receive. This allows the proxy server to respond to the frequently received requests and pass the other requests to the Web server. This is called a reverse proxy.
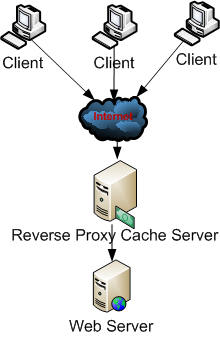
Fig 1.2 : Reverse Proxy Caching
Advantages
- Data that are cached on reverse proxy server can a accessed easily
- Web server reduce the number of request
Disadvantages
-
As the Server configured in front of Web sever some what it increases the network traffic.
4. Web Server Caching : In Web server caching cached data stored inside the web server, Data caching and page caching used web sever caching mechanism.
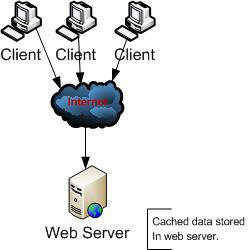
Fig 1.3 : Web Server Caching
Advantages
-
Improve the performance of sites by decreasing the round trip of data retrieving from database or some other server
Disadvantages
-
Increase the Network Load
Advantages and Disadvantages Of Caching
Advantages
- Reduced server load
- Reduced bandwidth consumption
ASP.NET provides support for page, partial page (Fragment), and data caching. Caching a page that is dynamically generated, called page output caching . In page caching when a pages is cached that dynamically generated only the first time it is accessed. Any subsequent access to the same page will be returned from the cache.. ASP.NET also allow to Cached a portion of a page called Partial page caching or Fragment Caching . Other server data are cached (e.g. SQL Server data, XML Data ) that can be easily accessed with out re-retrieving that data using data Caching . caching reduce number of round trip of database and other data source. ASP.NET provides a full-featured data cache engine, complete with support for scavenging (based on cache priority) , expiration, and file and key , Time dependencies . There are two locations where caching can be used to improve performance in ASP.NET applications.
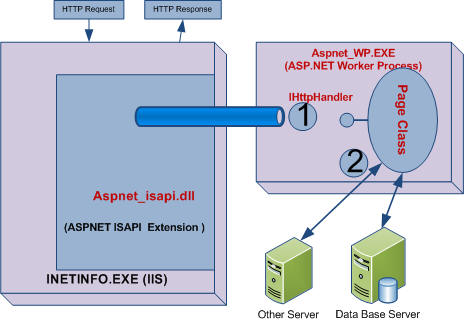
Fig 1.4 : Caching Opportunity in ASP.NET
In above picture (1) is used for return caching of page that means its used in output caching and (2) save the round trip by storing the data using data caching.
ASP.NET supports two types of expiration policies, which determine when an object will be expired or removed from the cache. These two policies are described as follows:
Absolute expiration: Determines that the expirations occur at a specified time. Absolute expirations are specified in full-time format (hh:mm:ss). The object will be expired from the cache at the specified time.
ASP.NET Supports Three Type of Caching
- Page Output caching [Output caching ]
- Fragment caching [Output caching ]
- Data Caching
1 . Page Output Caching : Before starting Page Output caching we need to know the compilation process of a page, because based on the generation of page we should able to understand why should we used caching . ASPX Page compiled in two stage process. First, the code is compiled into the Microsoft Intermediate Language (MSIL). Then, the MSIL is compiled into native code (by JIT Compiler ) during execution. and entire code in an ASP.NET Web page is compiled into MSIL when we built the sites , but at the time of execution only the portion of MSIL Converted to native code which is need by user or user request, which also improve performance.
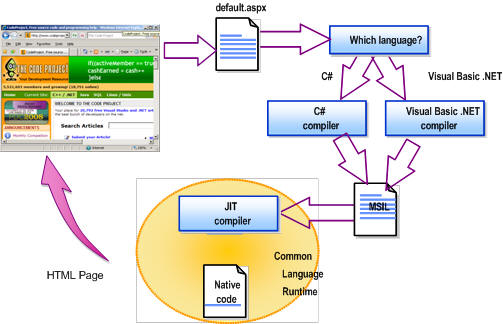
Fig 1.5 : ASP.NET Page Execution Process
Now what ever we are getting , if there is some page which change frequently JIT need compile every time. So, We can use Page output for those page which content are relatively static. So rather than generating the page on each user request we can cached the page using Page output caching so that it can be access from cache itself. so, Instead of pages can be generated once and then cached for subsequent fetches.Page output caching allows the entire content of a given page to be stored in the cache.
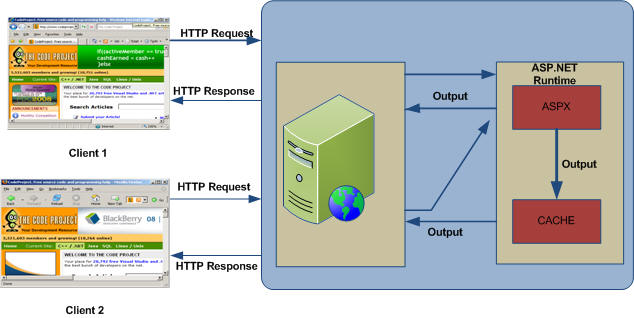
Fig 1.5 : Page Output Caching
As from given picture, when the first request is generated page is been cached and for same page request page should be retrieve from cache itself rather that regenerating the page.
For Output caching , OutputCache directive can be added to any ASP.NET page, specifying the duration (in seconds) that the page should be cached. The code.
Example
<%@ Page Language="C#" %>
<%@ OutputCache Duration='300' VaryByParam='none' %>
<html>
<script runat="server">
protected void Page_Load(Object sender, EventArgs e) {
lbl_msg.Text = DateTime.Now.ToString();
}
script>
<body>
<h3>Output Cache example</h3>
<p>Page generated on:
<asp:label id="lbl_msg" runat="server"/></p>
</body>
</html>
We also set Caching property from Codebehind also
void Page_Load(Object sender, EventArgs e) {
Response.Cache.SetExpires(DateTime.Now.AddSeconds(360));
Response.Cache.SetCacheability(
HttpCacheability.Public);
Response.Cache.SetSlidingExpiration(true);
_msg.Text = DateTime.Now.ToString();
}
We have to have mention the Duration and VaryByParam attributes. Duration Define how long time cache will persist. VaryByParam is meant for is there any change with parameter for cache.
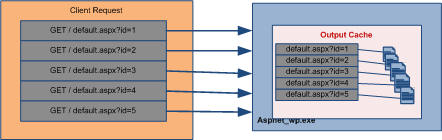
Fig 1.6 : Caching multiple page based on parameters
As above picture shown , if we are using query string for page and we need to cached all the page based on the query string, we have to use VaryByParam attributes of outputcache. Based on every query string data should be cached, and when user request page among those query string (id in picture) page should be fetched from cached. Following example describe the detsils use of VaryByParam Attributes.
Example:
<%@ OutputCache Duration="60" VaryByParam="*" %>
page would cached for 60 seconds, and would create a separate cache entry for every variation of querystring
Following table shown you the most commonly used and most important attributes of outputcache:
| Attribute | Values | Description |
| Duration | Number | Define how long page will be cached (in seconds) |
| Location | 'Any' 'Client' 'Downstream' 'Server' 'None' | It define the page cached location. I have discussed it later in details |
| VaryByCustom | 'Browser' | Vary the output cache either by browser name and version or by a custom string, |
| VaryByParam | 'none' '*' | This is a required attribute, which is required for parameter for the page. This I have already discussed. |
All the attributes that we specify in an OutputCache directive are used to populate an instance of the System.Web.HttpCachePolicy class by calling. The complete implementation of cache policies provided by ASP.NET is encapsulated in the HttpCachePolicy class. Following is the another implementation of caching from code behind.
Output Caching Location
As I have already mention We can store cached data in different location like client, server or in between client and server , Now I am going to discuss how this is feasible to set location of cached data. If we store the cached data it save the page rendering time by fetching the data from catch. There is another way that we can save cached data on client browser , which reduce the network traffic. OutputCache directive on a page enables all three types of caching—server, client, and proxy—by default.
Following Table shown you the Location details . It show the location of cached and what should be the effects on Cache-Control and Expires Header.
| Value of Location | Cache-Control Header | Expires Header | Page Cached on Server | Description |
| 'Any' | public | Yes | Yes | Page can be cached on the browser client, a downstream server, or the server |
| 'Client' | private | Yes | No | Page will be cached on the client browser only. |
| 'Downstream' | public | Yes | No | Page will be cached on a downstream server and the client |
| 'Server' | no-cache | No | Yes | Page will be cached on the server only. |
| 'None' | no-cache | No | No | Disables output caching for this page. |
For example, if you specified a value of 'Client' for the Location attribute of an OutputCache directive on a page, the page would not be saved in the server cache, but the response would include a Cache-Control header ( Pages can indicate whether they should be cached on a proxy by using the Cache-Control header.) value of private and an Expires header (HTTP response, indicating the date and time after which the page should be retrieved from the server again ) with a timestamp set to the time indicated by the Duration attribute
Example
<%@ OutputCache Duration='120' Location='Client' VaryByParam='none' %>
This would save the cached for 120 second and cached data should not be saved on Server it should store only on client browser.
2 . Page Fragment Caching : ASP.NET provides a mechanism for caching portions of pages, called page fragment caching. To cache a portion of a page, you must first encapsulate the portion of the page you want to cache into a user control. In the user control source file, add an OutputCache directive specifying the Duration and VaryByParam attributes. When that user control is loaded into a page at runtime, it is cached, and all subsequent pages that reference that same user control will retrieve it from the cache.
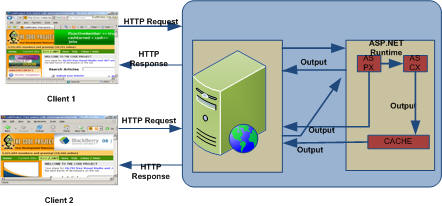
Fig 1.7 : Fragment Caching
Following Example shown you details of Fragment caching
Example
<!— UserControl.ascx —>
<%@ OutputCache Duration='60'
VaryByParam='none' %>
<%@ Control Language="'C#'" %>
<script runat="server">
protected void Page_Load(Object src, EventArgs e)
{
_date.Text = "User control generated at " +
DateTime.Now.ToString();
}
</script>
<asp:Label id='_date' runat="'server'" />
Here I have user caching on user control, so when ever we used in a page , only partial page will be cached.
3. Data Caching : Caching of data can dramatically improve the performance of an application by reducing database contention and round-trips. Simply data caching store the required data in cache so that web server did not send request to DB server every time for each and every request which increase the web site performance. For data caching we need to cached those data which is accessible to all or which is very common data. The data cache is a full-featured cache engine that enables you to store and retrieve data between multiple HTTP requests and multiple sessions within the same application .
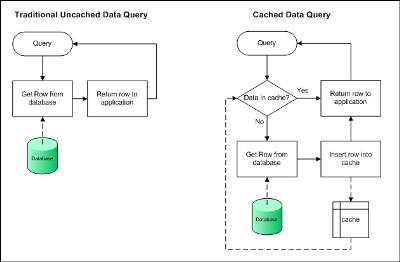
Fig 1.8 : Data Caching
Above image showing how data can be accessed directly from data base server and how data retrieving using cache. Data caching is not only related with SQL Server, we can store other data source data (as shown on Fig 1.4).
Now let see, how we can implement data caching in our web application. There are Three Different way to add data or object into cache. But based upon the situation we have to access it. These methods are Cache[], Cache.add(), cache.insert(). The following table will show you the clear difference of there methods.
| Stored data in cache | Support Depedency | Support Expiration | Support Priority Settings | Return Object |
| cache[] | Yes | No | No | No | No |
| cache.insert() | Yes | Yes | Yes | Yes | No |
| cache.add() | Yes | Yes | Yes | Yes | Yes |
As we are getting, cache[] is property that is very simple to use but cache.insert() and cache.add() are having some more property which give us more control on cached data.
Now we should look into details of Cache.Insert() and Cache.Add() methods. Cache.Insert() having 4 overloaded method where as Cache.Add() having no overloaded methods. Following table are showing are most commonly used important property for those methods.
| Property | Type | Description |
| Key | String | A unique key used to identify this entry in the cache |
| Dependency | CacheDependency | A dependency this cache entry has—either on a file, a directory, or another cache entry—that, when changed, should cause this entry to be flushed |
| Expires | DateTime | A fixed date and time after which this cache entry should be flushed |
| Sliding Expiration | TimeSpan | The time between when the object was last accessed and when the object should be flushed from the cache |
| Priority | CacheItemPriority | How important this item is to keep in the cache compared with other cache entries (used when deciding how to remove cache objects during scavenging) |
| OnRemoveCallback | CacheItem RemovedCallback | A delegate that can be registered with a cache entry for invocation upon removal |
Cache.Insert() Method
[Cache.Insert() Code Example]
First two are the mandatory for Cache.Insert() methods, whereas others vary based on the situation.
Using Cache dependency we can set the dependency of the catch with some data or entity to changed. So we can set the depedency of cache by which we can update, remove cache. There are three types of dependencies supported in ASP.NET.
- File based Dependency
- Key Based Dependency
- Time Based Dependency
File Based Dependency : File-based dependency invalidates a particular Cache item when a file(s) on the disk changes.
Using cache dependency we can force ASP.NET to expire the cached data item from the cache when the dependency file changes. We can set Dependency to multiple file also . on such case dependency should be built from an array of files or directories.
Use : File based dependency is very use full when need to update some data that displaing to the user based on some changed on file. As for Example, a New Sites always shows data from a file , now if some breaking news come, they just update the file and cached should expire and during the expire time we can reload the cache with updated data using OnRemoveCallBack
Key Based Dependency : Key-based dependency invalidates a particular cache item when another cache item changes.
Use : This is use full when we have multiple interrelated object are in cache and if one of the object changed we need to updated or expire all of them, Key Based Dependency will be best option
Time Based Dependency : Time-based dependency causes an item to expire at a defined time. Cache.Insert() method of the Cache class is used to create a time-based dependency. Two Types of Time based Dependency are available.
Absolute: Sets an absolute time for a cache item to expire. Absolute expirations are specified in full-time format (hh:mm:ss). The object will be expired from the cache at the specified time.
Sliding: Resets the time for the item in the Cache to expire on each request. This is useful when an item in the cache is to be kept alive so long as requests for that item are coming in from various clients.
With those dependency ASP.NET also support
In addition to the dependencies, ASP.NET allows the following:
Automatic expiration: The cache items that are underused and have no dependencies are automatically expired.
Support for callback: The Cache object can be configured to call a given piece of code that will be executed when an item is removed from the cache. This gives you an opportunity to update the cache. We can use OnRemoveCallback().
Caching Considerations
-
Enable output caching on a page that is frequently accessed and returns the exact same contents for many of those accesses
-
When enabling output caching for a page, be sure not to introduce incorrect behavior and/or rendering for any particular client.
-
Determine the duration of the cached page carefully to balance speed of access (throughput) with memory consumption and cache coherency correctness.
-
Consider enabling sliding expiration on a page if you end up using VaryByParam='*'.
-
The data cache is not a container for shared updateable state.
-
Cache data that is accessed frequently and is relatively expensive to acquire.
-
If data is dependent on a file, directory, or other cache entry, use a CacheDependency to be sure it remains current.
| Situation | Suggested Caching Type |
| The generated page generally stays the same, but there are several tables shown within the output that change regularly. | Use Fragment Caching in this situation. |
| The generated page constantly changes, but there are a few objects that don’t change very often. | Use Data Caching for the objects. |
| The generated page changes every few hours as information is loaded into a database through automated processes. | Use Output Caching and set the duration to match the frequency of the data changes. |
